# python学习
# Python3基础语法
# 编码设置
默认是utf-8,也可以更改
# -*- coding: GBK -*-
print("改成中文编码")
# 变量名
第一个是字母或下划线_
第一个字母以外的字符可以为字母、数字和下线线组成
大小写敏感
在python 3版本,非ascii标识符也可以作为变量名,例如中文
# 保留字
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', '__peg_parser__', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally',
'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
# 注释
单行注释用#组成
# 我是单行注释1 # 我是单行注释2多行注释用三个单引号或三个双引号组成
''' 我是注释块 我想写啥就写啥 哈哈 '''""" 我也是注释块 我想写点东西在这里 也是可以的哦 """指定python的运行版本是用#!开头的设置
#!/usr/bin/python3 print("指定python3版本执行")或
#!/usr/bin/env python3 print("指定python3版本执行")指定文件编码,在第一行用#开头设置
# -*- coding: GBK -*- print("改成中文编码")
# 行与缩进
代码块是通过缩进来表示(同级的缩进空格数要相同),和yaml文件一样,不需要大括号{}。
if True:
print("true!")
else:
print("false")
print("false2")
print("complete!!")
# 多行语句
多行语句用反斜杠\来实现
num1 = 1
num2 = 6
num3 = 3
sum1 = num1 \
+ num2 \
+ num3
print(sum1)
在[],{},()中的多行语句,不需要反叙杠\
strArr = ['item1', 'item2' ,'item3', 'item4' ,'item5']
# 数字(Number)类型
数字类型有4种:整型、布尔型、浮点数、复数
- int(整型):1,2,3,5,6等,也就是整数
- bool(布尔型):True,False
- float(浮点数):1.23,5E-2
- complex(复数):1+2j、1.2+2.5j
# 字符串(String)
- 单引号和双引号使用完全相同。
- 多行字符串使用三引号指定(''' or """)
- 反斜杠\是转义符
- 使用r禁用反斜杠的转义(raw string),即所见输出。r'Liu \Mingyun\n',所见输出Liu \Mingyun\n
- 按字面意义级联字符串,如"Liu " "ming ""yun"会自动转换为 Liu ming yun
- 字符串可以用+运算符连接,用*运算符重复。
- 字符串有两种索引方式,从左往右0开始,从右往左-1开始
- 字符串不能改变
- 没有单独的字符类型,一个字符就是长度为1的字符串。
- 字符串的截取语法格式:变量[头下标:尾下标:步长] (不包括尾下标字符)
# 空行
类的方法或函数之间用空行分隔,便于代码的维护和重构。
# 等待用户输入
/usr/bin/python3
input("按下enter键后退出:\n")
# 同一行写多条语句
用分号;分割
x=13; print(x)
# 多个语句构成代码组
缩进相同的一组语句构成代码组。像if/elif/else、while、def和class这样的复合语句,首行以关键字开始,以冒号(:)结束,该行之后的一行或多行代码构成代码组。首行及后面的代码组组成一个子句(clause)。
if x<0 :
<doit>
elif x=0 :
<doit2>
else :
<do other>
# print输出
默认是输出后换行,要实现不换行需要加上end=""
x="abcd"
print(x)
print(x)
print(x,end="")
print(x,end=",")
#打印空行
print()
# import与from...import
- import
: 导入整个模块 - from
import , ,... : 从某个模块导入一个或多个函数 - from
import * :导入某个模块的全部函数
# 命令行参数
py -h
# Python3基本数据类型
# 变量赋值
# 变量赋值
print('变量赋值')
counter = 100 # 整型变量
miles = 1000.0 # 浮点型变量
name = 'mofar' # 字符串
print(counter, miles, name, sep='\n')
# 多个变量赋值
print('多个变量赋值')
val1 = val2 = val3 = 13
val4, val5, val6 = 14, 15, 'Mofar'
print(val1, val2, val3)
print(val4, val5, val6)
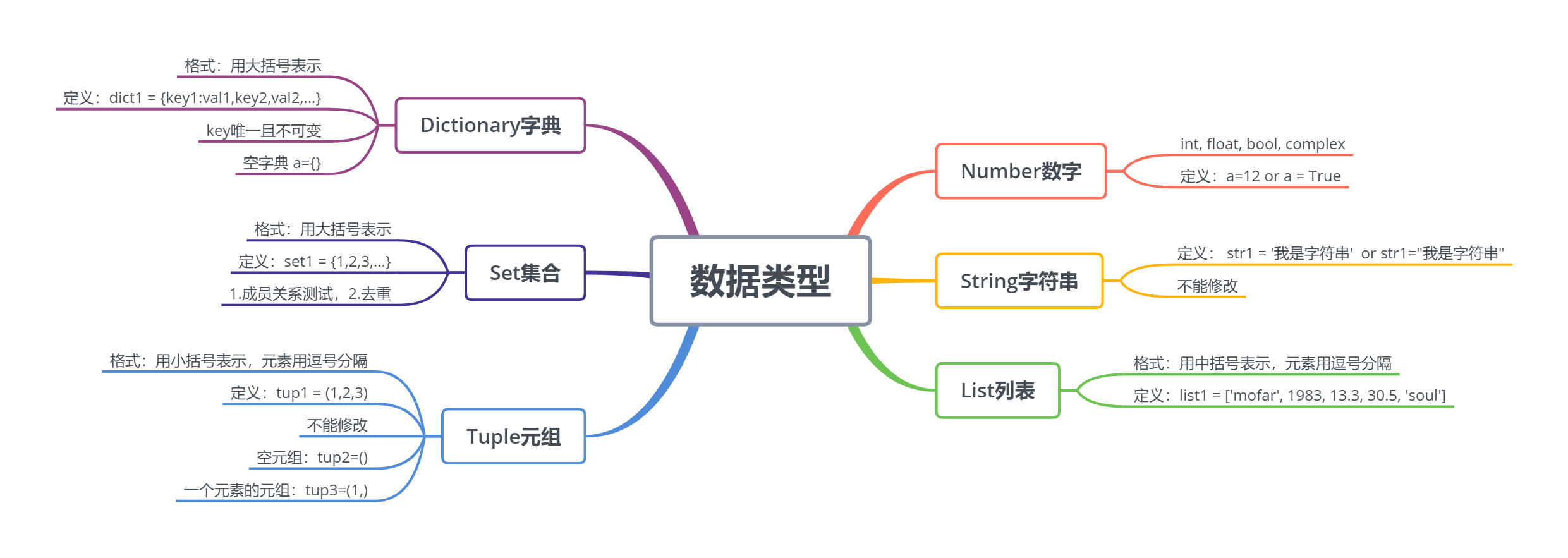
# 标准数据类型
一共六个:Number(数字),String(字符串),List(列表),Tuple(元组),Set(集合),Dictionary(字典)
不可变数据(3个):Number(数字),String(字符串),Tuple(元组)
可变数据(3个):List(列表),Set(集合),Dictionary(字典)
# Number(数字)
包括int(长整型), float(浮点型), bool(布尔型), complex(复数)四种类型,可以用type()函数查询变量的类型。
a, b, c, d = 13, 15.4, True, 5+4j
print(type(a),type(b),type(c),type(d))
isinstance(a,int) # True
del a, b
- type()不会认为子类是一种父类类型
- isinstance()会认为子类是一种父类类型
>>> 5 + 3 # 加法
8
>>> 4.5 - 2 # 减法
2.5
>>> 3 * 7 # 乘法
21
>>> 2 / 4 # 除法,结果浮点数
0.5
>>> 2 // 4 # 除法,结果一个整数
0
>>> 17 % 3 # 取余
2
>>> 2 ** 5 # 乘方
32
- 运算符号:+、-、*、**(乘方)、/、//(求整)、%(求余)
- 只可以同时为多个变量赋值:a, b, c = 1, 2, 3
- 一个变量可以通过赋值指向不同类型的对象
- 除法包含两个运算符:/(常规除法),//(整数部分 ,商),%(余数)
- 在混合计算时,整型自动转换成浮点数
# String(字符串)
使用单引号('')或双引号("")括起来,反斜杠(\)转义特殊字符
字符串截取语法:变量[开始下标:结束下标:步长]
- 下标索引左往右由0开始,右往左由-1开始。
- 步长默认为1。
- 加号
+是字符串的连接符,星号*是复制当前字符串,后接数字为复制的次数。- 字符串不能改变,例如str1[4]='k',会提示错误。
- 反斜杠可以用来转义,使用r可以让反斜杠失去转义。
#!/usr/bin/python3
str = 'mofar123456'
print(str) # 输出字符串
print(str[0]) # 截取第一个字符
print(str[0:-1]) # 截取第一个到倒数第二个之间的字符
print(str[1:4]) # 截取第2个到第4个字符
print(str[1:7:2]) # 截取第2个到第7个字符之间的1,3,5
print(str[1:]) # 截取第2个到结束的全部字符
print(str * 2) # 输出字符串两次,也可以写成print(2 * str)
print(str+' Test') #连接字符串
# List(列表)
语法格式:
变量[头下标:尾下标:步长]
- List很多特性和String相同。
- 索引值以0为开始值,-1为从末尾的开始值。
- 加号
+是列表连接运算符,星号*是重复操作。- 与字符串不一样的是:列表中的元素是可以修改的。
- List写在方括号之间,元素用逗号隔开。
- 和字符串一样,list可以被索引和切片。
- 如果步长为负数表示逆向读取
#!/usr/bin/env python3
list1 = ['mofar', 1983, 13.3, 'soul', 20.5]
list2 = [123, 'liumingyun']
print(list1) # 输出完整的列表['mofar', 1983, 13.3, 'soul', 20.5]
print(list1[1]) # 输出第2个元素1983
print(list1[2:4]) # 输出第3、4个元素[13.3,'soul']
print(list1[3:]) # 输出第4个元素开始的所有元素['soul',20.5]
print(list2 * 2) # 输出两次列表
print(list1 + list2)# 连接列表
>>> list3 = [1,2,3,4,5,6]
>>> list3[0] = 0
>>> a[2:5] = [22:33:44]
>>> a
[0, 2, 22, 33, 44, 5, 6]
>>> a[2:5]=[] #将对应的元素值设置为[],即删除元素
>>> a
[0, 2, 5, 6]
# 如果步长为负数表示逆向读取
>>> words = ['liu', 'ming', 'yun', 'soul', 'mofar']
>>> print(words[-1::-1])
['mofar', 'soul', 'yun', 'ming', 'liu']
# Tuple(元组)
元组(Tuple)与列表类似,不同之处是元组的元素值不能修改。元组写在小括号()里,字符串是一种特殊的元组。
>>> tup1 = (1,2,3,4,5,6)
>>> print(tup1[0])
1
>>> print(tup[1:5])
(2, 3, 4, 5)
>>> tup[0] = 12 # wrong
>>> list1 = ['a', 'b', 'c', '1']
>>> tup2 = (1, list1, 2, 'mofar')
>>> list1[3] = 'd'
>>> print(tup2)
(1, ['a', 'b', 'c', 'd'], 'soul')
tup2 = () # 空元组
tup3 = (1,) # 一个元素的元组,需要在元素后添加一个逗号
- 元组用()表示,构造0或1个元素的元组比较特殊,空元组:(),一个元素的元组是(val,)。
- 元组的元素值不能修改,但是可以存在可变的元素(例如list)。
- string、list和tuple都属于sequence(序列)。
- 元组可以被索引和截取,和string一样。
- 元组也可以使用+操作符进行拼接。
# Set(集合)
由一个或数个形态各异的大小整体组成的,构成集合的事物或对象称作元素或成员。
基本功能:
- 进行成员关系测试
- 删除重复元素
语法:
set1 = {val1,val2,...}
或
set(val)
#!/usr/bin/env python3
set1 = {'aa', 'c' , 'd', 1, 2, 3, 'a', 'd', 'c', 'aa', 'g', 4, 3, 5, 2, 3, 1, 'g'}
# 去重
print(set1)
# 成员测试
if 'a' in set1:
print('a is in set')
else:
print('a is not in set')
# set()定义并进行集合运算
a = set('abracadabra')
b = set('alacazam')
print(a)
print(type(a))
print(a - b) # 差集
print(a | b) # 并集
print(a & b) # 交集
print(a ^ b) # 不同时存在的元素
# result:
# {1, 2, 3, 4, 5, 'aa', 'a', 'c', 'g', 'd'}
# a is in set
# {'a', 'c', 'r', 'd', 'b'}
# <class 'set'>
#{'b', 'r', 'd'}
# {'m', 'a', 'c', 'r', 'z', 'd', 'l', 'b'}
# {'a', 'c'}
# {'d', 'z', 'r', 'm', 'l', 'b'}
# Dictionary(字典)
key-value键值对,其实类似是json。
格式:
dict1 = {'key1': 'val1','key2': 'val2',...}
或
dict([('key1', 'val1'),('key2', 'val2'),('key3','val3')])
- key必须使用不可变类型。
- key必须是唯一的
- 空字典: a = {}
#!/usr/bin/python3
dict1 = {}
dict1['one'] = '测试字母1'
dict1[2] = '测试数字2'
dict2 = {'name': 'limingyun', 'code': 102, 'age': 38, 'site': 'mofar.top'}
print(dict1['one'])
print(dict1[2])
print(dict2)
print(dict2.keys())
print(dict2.values())
#result:
'''
测试字母1
测试数字2
{'name': 'limingyun', 'code': 102, 'age': 38, 'site': 'mofar.top'}
dict_keys(['name', 'code', 'age', 'site'])
dict_values(['limingyun', 102, 38, 'mofar.top'])
'''
构造函数dict()可以从键值对序列构建字典:
>>> dict([('key1',1), ('key2', 'liu'),('key3',3)])
{'key1': 1, 'key2': 'liu', 'key3': 3}
>>> {x: x**2 for x in (2, 3, 4)}
{2: 4, 3: 9, 4: 16}
>>> dict(key1=1,key2=2,key3=4)
{'key1': 1, 'key2': 2, 'key3': 4}
- 字典有一些内置函数:clear(), keys(), values等
- 字典是一个映射类型,它的元素是键值对。
- 字典的关键字必须为不可变类型,且不能重复。
- 创建空字典使用{}
# 数据类型总结
# Python3数据类型转换
数据类型的转换只需要将数据类型作为函数名即可。转换后返回一个新的对象表示转换的值。
| 函数 | 描述 |
|---|---|
| int(x[,base]) | 将x转换为一个整数 |
| float(x) | 将x转换到一个浮点数 |
| complex(real[,imag]) | 创建一个复数 |
| str(x) | 将对象x转换为字符串 |
| repr(x) | 将对应x转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列s转换为一个元组 |
| list(s) | 将序列s转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d必须是一个(key,value)元组序列 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
# Python3解释器
# 交互式编程
$ python3
>>> print("hello world!")
# 脚本式编程
print("hello world")
#保存到hello.py
python3 hello.py
# Python3运算符
# 1.算术运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加:两个对象相加 | 1+2=3 |
| - | 减:得到负数或是一个数减去另一个数 | -11或11-15=-4 |
| * | 乘:两个楼相乘或返回一个被重复若干次的字符串 | 2*3=6或“2”*3="222" |
| / | 除:x除以y | 13/4=3.25 |
| % | 取模:返回除法的余数 | 13%4=1 |
| ** | 幂:返回x的y次幂 | 3**3=27 |
| // | 取整除:往小的方向取整数 | 7//3=2或-7//3=-3 |
# 2.比较(关系)运算符
x=12; y=10
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于:比较两个对象是否相等 | x==y; return False |
| != | 不等于:比较两个对象是否不等 | x!=y; return True |
| > | 大于:比较x是否大于y,x>y | x>y;return True |
| < | 小于:比较x是否小于y,x<y | x<y; return False |
| >= | 大于等于:比较x是否大于等于y | x>=y;return True |
| <= | 小于等于:比较x是否小于等于y | x<=y;return Flase |
# 3.赋值运算符
x=3;y=5
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | z = x + y或x=3 |
| += | 加法赋值运算符 | x+=y; 等价于x=x+y |
| -= | 减法赋值运算符 | a-=b 等价于a=a-b |
| *= | 乘法赋值运算符 | a*=b等价于a=a**b |
| /= | 除法赋值运算符 | a/=b 等价于 a=a/b |
| %= | 取模(余)赋值运算符 | a%=b 等价于 a=a%b |
| **= | 幂赋值运算符 | a**=b 等价于 a=a**b |
| //= | 取整除赋值运算符 | a//=b 等价于a=a//b |
| := | 海象运算符,在表达式内部为变量赋值 | a=128*(b:=10) 等价于b=10;a=128*10 |
# 4.位运算符
x=6;y=4
二进制表示分别为x=110;y=100
| 运算t符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符,位同1则1,位见0则0 | x&y=4,即二进制的100 |
| | | 按位或运算符,位同0则0,位见1则1 | x|y=6,即二进制的110 |
| ^ | 按位异或运算符,位同则0,位异则1 | x^y=2,即二进制的10 |
| ~ | 按位取反运算符:即0变1,1变0,~x等于-x-1 | ~x=-7,即二进制的1000,有符号二进制数的补码形式,第一位是符号位 |
| << | 左移运算符;全部位左移若干(右数)位,高位丢弃,你们补0,移n位等价于乘以2的n次方 | a<<2 结果24,二进制:110000 |
| >> | 右移运算符:全部位右移若干(右数)位,右移n位等价于整除2的n次方 | a>>2 结果1,二进制:1 |
# 5.逻辑运算符
x=3; b=28
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔“与” :如果x为False,它返回x的值,否则返回y的值 | x and y 返回28 |
| or | x or y | 布尔“或”:如果x是True,它返回x的值,否则返回y的计算值 | x or y 返回3 |
| not | not x | 布尔“非”:如果x为True,返回False,如果x为False,返回True | not x 返回Flase |
其实也叫短路逻辑运算符,即一边的条件计算结果能确定表达式的结果,即返回,不再计算后面的条件。
and 的表达式,x如果为False时,无论y是什么值都不影响整个表达式的结果,所以直接返回x,否则返回y。
or的表达式,如果x为True时,即可确定整个表达式的结果为True了,所以会直接返回x,否则返回y。
#
# 6.成员运算符
x = 3; y = 28
list = [1, 3, 45, 27, 30]
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果是指定序列的成员,则返回True,否则返回False | x in list 返回True |
| not in | 如果不是指定序列的成员,返回True,否则返回False | y not in list 返回True |
# 7.身份运算符
x=3;y=3
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | 判断两个标识符是不是引用自一个对象 | x is y类似id(x)==id(y),返回True |
| is not | 判断两个标识符是不是引用自不同对象 | x is not y,类似id(x)!=id(y),返回False |
id(x) 函数用于获取对象的内存地址。
# 8.运算符优先级
| 运算符 | 描述 |
|---|---|
| (expressions...), [expressions...], (key: value...), {expressions...} | 括号表达式 |
| x[index], x[index1:index2], x(arguments...), x.attribute | 读取,切片,调用,属性引用 |
| await x | await表达式 |
| ** | 乘方(指数),幂 |
| +x, -x, ~x | 正数,负数,按位取反 |
| *, @, /, //, % | 乘,矩阵乘,除,整除,取余 |
| +, - | 加减 |
| <<, >> | 移位 |
| & | 按位与 AND |
| ^ | 按位异或 XOR |
| | | 按位或 OR |
| in, not in, is , is not, <, <=, >, >=, !=, == | 比较运算,包括成员检测和标识号检测 |
| not x | 逻辑非 NOT |
| and | 逻辑与 AND |
| or | 逻辑或 OR |
| if else | 条件表达式 |
| lambda | lambda表达式 |
| := | 赋值表达式 |
# Python3条件控制
# 1. if语句
if 表达式1:
print("表达式1为True")
print("进入了1")
else 表达式3:
print("表达式3为True")
print("进入了3")
if 表达式1:
print("表达式1为True")
print("进入了1")
elif 表达式2:
print("表达式2为True")
print("进入了2")
else 表达式3:
print("表达式3为True")
print("进入了3")
注意点:
- 条件后面用冒号
:- 使用缩进划分语句块,相同缩进数的语句组成一个语句块
# 2.if嵌套语句
if ...:
print("进入if语句...")
if ...:
print("进入嵌套语句")
else
print("进入嵌套语句2")
elif ...:
print("我是elif啊")
else ...:
print("运行到else啦")
# 3.match...case
相当于switch...case语句,
case _相当于default,不需要break中断
match 变量:
case 值1:
doSomething1
case 值2:
doSomething2
case 值3|值4|值5:
doSomething345
case _:
print("其它都不匹配,默认就执行我!")
注意:
- match相当于switch
- case语句执行完后面不用
breakcase _相当于default- 一个case里可以用
|隔开设置多个匹配条件。
# Python3循环语句
关键字:
for in else while break continue pass range()
# 1.while循环语句
while 判断语句:
执行语句块
a=1
while a<10:
print(a)
a+=1
注意
- 没有 do...while循环语句
- 注意冒号
:
# 2.while...else循环语句
while 判断语句:
#执行语句块
else:
#循环结束(不是break中断)后执行的语句块
# 3.for...in循环语句
for <i> in <序列或数组或字符串等>:
#执行的语句块
for i in range(10,12):
print(i)
##结果(range函数不包尾)
10
11
##----##
list = ["liu","ming","yun"]
for i in list:
print i
##结果
liu
ming
yun
##-----##
for i in "liu":
print(i)
##结果
l
i
u
# 4.for...in...else循环语句
for i in <序列或数组或字符串等>:
#循环主体
else:
#循环结束(非break中断结束)后执行的代码块
# 5. break,continue与else语句块
- break: 跳出当前循环(循环中止),并跳过else的代码块。
- continue: 跳过当前循环中的剩余语句块,进入下一轮循环。
# 6. pass空语句
pass不做任何事,相当于oracle的存储过程中的
null;语句,一般用来做占位语句
# Python3推导式
推导式是一种独特的数据处理方式 ,可以从一个数据序列构建另一个新的数据序列的结构体。
- 列表(list)推导式
- 字典(dict)推导式
- 集合(set)推导式
- 元组(tuple)推导式
##格式
## ... for ... in ...
## ... for ... in ... if ...
# 1.列表[1,2...]推导式
[1,2,3......]
for ... in ... if ...
[处理变量的表达式 for 变量 in 原始列表]
[out_exp_res for out_exp in input_list]
or
[处理变量的表达式 for 变量 in 原始列表 if 满足的条件]
[out_exp_res for out_exp in input_list if condition]
##out_exp_res:列表生成元素的表达式,可以是有返回值的函数。
##for out_exp in input_list: 循环input_list将out_exp传入到out_exp_res
##if condition: 条件语句,过滤列表中不符合条件的值。
my_names = ["liu","ming","yun","soul","mofar"]
new_names = [name.upper() for name in my_names if ("l" in name)]
print(new_names)
##结果
['LIU','SOUL']
# 2.字典{(key:value)}推导式
- {key1:value1,key2:value2....}
- {key_expression: value_expression for ... in ... }
- {key_expression: value_expression for ... in ... if...}
{key_expr:value_expr for value in collection }
or
{key_expr: value_expr for value in collection if condition}
#示例
names = ["liu","ming", "yun", "soul","mofar"]
new_dict = {name:name.upper()*2 for name in names if len(name)<4}
print(new_dict)
# 3.集合{1,2...}推导式
{ expr for item in seq }
or
{ expr for item in seq if cond}
new_set = {i**i for i in range(4)}
print(new_set)
##结果
{1, 4, 27}
# 4.元组推导式(生成器表达式)
元组推导式返回的结果是一个生成器对象,需要用tuple()函数将生成器对象转换成元组。
(expr for item in seq)
or
(expr for item in seq if cond)
new_tuple = (i**i for i in range(4))
print(new_tuple)
print(tuple(new_tuple))
##
<generator object <genexpr> at 0x000002A161CBE190>
(1, 1, 4, 27)
生成器对象只能调用一次(其实就是迭代器)
# Python3迭代器与生成器
# 1.迭代器
- 是访问集合元素的一种 方式,
- 是一个可以 记住遍历位置的对象。
- 有两个基本方法:iter()和next()
- 字符串,列表和元组对象都可以用于创建迭代器
list = ['liu','ming','yun']
it = iter(list)
print(next(it))
#output liu
print(next(it))
#output ming
print(next(it))
#output yun
it2 = iter(list)
#for语句进行遍历
for x in it2:
print(x,end=" ")
#output liu ming yun
import sys
it3 = iter(list)
#while循环
while True:
try:
print(next(it),end=" ")
except StopInteration:
sys.exit()
#output liu ming yun
# 2.创建迭代器
1.要实现两个方法:
__iter__()和__next()__
class odd:
def __iter__(self):
self.num = 1
return self
def __next__(self):
s = self.num
self.num += 2
return s
myOdd = odd()
myit = iter(myOdd)
print(next(myit),next(myit),next(myit),next(myit))
#output 1 3 5 7
# 3.StopIteration
- 用于标识迭代的完成,防止出现无限循环的情况
- 在__next__()方法中设定触发StopIteration异常来结束迭代
class odd:
def __iter__(self):
self.num = 1
return self
def __next__(self):
if self.num <=5
s = self.num
self.num += 2
return s
else
raise StopIteration
myOdd = odd()
myit = iter(myOdd)
for i in myit:
print(i)
#output 1 3 5
# 4.生成器
#!/usr/bin/python3
import sys
def fibonacci(n): #斐波那契 生成器函数
x, y, count = 0, 1, 0
while True:
if (count > n):
return
yield x
x, y = y, x + y
count += 1
f = fibonacci(10)
while True:
try:
print(next(f),end="")
except StopIteration:
sys.exit()
# Python3函数
- 函数以def关键词开头,后接函数名称和小括号
- 参数放在在小括号里面
- 函数第一行可以放函数注释,说明函数的功能
- 函数内容以
:开始,并且缩进return结束函数
def min(a,b):
#比较两个数的大小,返回最小值
if a < b:
return a
else:
return b
# 1.语法格式
def 函数名(参数列表):
函数体
# 2.函数调用
#!/usr/bin/python
def sayhi(name):
#say hi to <name>
print("hi:",name)
return
#调用函数
sayhi("soul")
sayhi("刘明云")
#output hi:soul
#output hi:刘明云
# 3.参数传递
- python里的变量是没有类型的
- 对象有不同的类型
#!/usr/bin/python
x = ['a','b','c']
x = "mofar"
#变量x是没有类型的,它是一个对象的引用(或叫指针),可以指向任何类型的对象
# ['a','b','c']是List类型
# "mofar"是String类型
# 可变对象与不可变对象
1.不可变对象: strings ,tuples,numbers,此值传递给函数,在函数内修改不影响原对象,即值传递
2.可变对象:list,dict等,传递的是一个引用,在函数内部修改此对象里面的内容时,会影响到原对象,即引用传递
# 传不可变对象实例
通过
id()函数查看内在地址的变化
def same_obj(x):
print(id(x))
x=13
print(id(x))
x=10
print(id(x))
same_obj(x)
#140726429152328
#140726429152328
#140726429152424
# 传可变对象实例
- 可变对象在函数里修改了参数,在调用这个函数的函数里,原始的参数也改变
#!/usr/bin/python
#改变列表的值
def chg_list(list):
list.append([13,14,15])
print("函数内取值:", list)
return
#调用函数
list=[1,2,3]
chg_list(list)
print("函数外取值:",list)
#output
#函数内取值:[1,2,3,[13,14,15]]
#函数外取值:[1,2,3,[13,14,15]]
# 4.参数
调用函数可使用的正式参数类型有:必需参数,关键字参数,默认参数,不定长参数
# 必需参数
必需参数要以正确的顺序传入函数,调用时的数量必须和声明时一样,否则语法错误。
# 关键字参数
- 函数调用使用关键字参数来确定全篇的参数值。
- 使用关键字参数允许函数调用时参数的顺序与声明时不一致,解释器可以 用参数名匹配参数值
#!/usr/bin/python
def hello(first_name,last_name):
print('hello:',first_name,last_name)
return
hello(last_name='默远',first_name = "刘")
# 默认参数
1.函数定义时,参数指定默认值,调用时不传入则用默认值
2.默认参数必须放在参数列表的最后面
#!/usr/bin/python
def hello(first_name,last_name="Mofar"):
print('hello:',first_name,last_name)
return
hello(first_name='刘')
#!/usr/bin/python
def hello(first_name='刘',last_name): #会报错,SyntaxError: non-default argument follows default argument
print('hello:',first_name,last_name)
return
hello(last_name='默远')
# 不定长参数
- 即可变参数,在变量名前加
*号- 以元组的形式传入,可以是空元组(调用时不传参)
- 类似java的可变参数
def fn_name([args,] *other_tuple_args):
fn_body
return [expression]
#!/usr/bin/python
def print_test(arg1, *vartuple):
"打印参数"
print("输出:")
print(arg1)
print(vartuple)
print_test(12,33,45)
#输出:
12
(33, 45)
- 带两个星号
**的参数语法- 参数会以字典的形式传入
def fn_name([args,] **args_dict)
fn_body
return [expression]
#!/usr/bin/python
def print_info(arg1, **arg_dict):
"打印参数"
print("输出:")
print(arg1)
print(arg_dict)
print_info(13,a=10,b=13)
- 参数中可以 单独出现
*号- 单独出现
*号参数时,*星号后面的参数必须要用关键字传入,也就是指定参数值是哪个参数名的。
#!/usr/bin/python
def fn(x,y,*,z):
print(x,y,z)
return
fn(1,2,3) #error
fn(1,2,z=4)
#output 1,2,4
fn(1,2,34,z=5)
#output
# 5.匿名函数
- 使用
lambda来创建匿名函数lambda只是一个表达式lambda的主体是一个表达式,而不是代码块。仅能在lambda表达式中封装有限的逻辑。
# 语法
lambda [arg1 [,arg2,...argn]]:expression
x = lambda m,n:m*2+n
print(x(1,2))
#output 4
#将匿名函数封装在函数内,通过传入不同的参数创建不同的匿名函数
def fn_power(n):
return lambda a : a**n
square = fn_power(2)
cube = fn_power(3)
print(square(10))
print(cube(10))
#output
#10
#100
# 6.return语句
- return [expression] 用于退出函数,并可返回一个表达式
- 不带表达式的return语句返回None
#!/usr/bin/python
def sum(x, y):
total = x + y
print("函数内打印total值:",total)
return total
total = sum(3,4)
print("函数外打印total值:",total)
#output
#函数内打印total值: 7
#函数外打印total值: 7
# 7.强制位置参数
- 形参语法
/用来指明/符号前的函数形参必须使用指定位置参数,不能使用关键字参数的形式*符号后的函数形参必须使用关键字形参。
#!/usr/bin/python3
def fn(a,b,/,c,d,*,e,f):
print(a,b,c,d,e,f)
return
#/符号前的a和b只能用位置形参,e和f只能用关键字形参,c和d两者都能用
fn(1,2,3,4,e=5,f=6)
fn(1,2,c=3,d=4,e=5,f=6)
fn(1,2,c=3,d=4,f=6,e=5)
# Python3数据结构
# 1.列表(List)
- 列表是可变的
列表的方法
| 方法 | 描述 |
|---|---|
| list.append(x) | 添加元素x到列表的结尾,相当于list[len(list):]=[x] |
| list.extend(other_list) | 合并两个列表,list[len(list):]=L |
| list.insert(i,x) | 在位置i插入元素x,指定位置大于list的长度,会自动append到list的结尾相当于list.append(x) |
| list.remove(x) | 删除第一个值为x的元素,没找到则返回错误 |
| list.pop(i)或list.pop() | 移除位置i的元素并返回,i为空则移除最后一个元素并返回 |
| list.clear() | 清空列表 |
| list.index(x) | 返回列表中第一个值为x的元素的索引,没找到则返回错误 |
| list.count(x) | 返回列表中元素值x出现的次数 |
| list.sort() | 排序,修改原列表 |
| list.reverse() | 反转列表的元素顺序,直接修改原列表 |
| list.copy() | 返回列表的浅复制,等于list[:] |
# 2.将列表当堆栈使用
- 堆栈属于先进后出
- 用append(x)进栈
- 用pop()出栈
>>> stack = [1,2,3]
>>> stack.append(4)
>>> stack.append(5)
>>> stack
[1, 2, 3, 4, 5]
>>> stack.pop()
5
>>> stack
[1, 2, 3, 4]
>>> stack.pop()
4
>>> stack
[1, 2, 3]
# 3.将列表当队列使用
- 队列是先进先出
- 用append(x)进栈
- 用pop(0)出栈
- 列表用作队列性能不高
>>> queue = [1,2,3,4,5]
>>> queue.append(6)
>>> queue.append(7)
>>> queue
[1, 2, 3, 4, 5, 6, 7]
>>> queue.pop(0)
1
>>> queue
[2, 3, 4, 5, 6, 7]
>>> queue.pop(0)
2
>>> queue
[3, 4, 5, 6, 7]
# 4.列表推导式
- 从序列创建列表的途径
- 每个推导式都可以有多个
for...in...if字句
>>> list = [1,2,3]
>>> [x**x for x in list]
[1, 4, 27]
>>> [[x, x**x] for x in list]
[[1, 1], [2, 4], [3, 27]]
>>> str = ['liu','ming','yun']
>>> [x.upper() for x in str if len(x)<4]
['LIU', 'YUN']
#二维矩阵列表的元素数是笛卡尔乘积
>>> list1 = [1,2,3]
>>> list2 = [4,5,6]
>>> [[x,y,x+y] for x in list1 for y in list2]
[[1, 4, 5], [1, 5, 6], [1, 6, 7], [2, 4, 6], [2, 5, 7], [2, 6, 8], [3, 4, 7], [3, 5, 8], [3, 6, 9]]
>>> [[x,y,x+y] for x in list1 for y in list2 if y<6]
[[1, 4, 5], [1, 5, 6], [2, 4, 6], [2, 5, 7], [3, 4, 7], [3, 5, 8]]
# 5.嵌套列表解析
- 支持多维列表,即矩阵列表
>>> matrix_list = [[1,2,3],[4,5,6]] #2*3的矩阵列表
>>> [[r[i] for r in matrix_list ] for i in range(3)]
[[1, 4], [2, 5], [3, 6]]
# 6.del语句
- 删除实体变量
- 根据索引删除元素
>>> list = [1,2,3,4,5,6]
>>> del list[2] #删除索引2的位置的元素
>>> list
[1, 2, 4, 5, 6]
>>> list.insert(2,3) #在索引2的位置插入3
>>> list
[1, 2, 3, 4, 5, 6]
>>> del list[1:4] #删除索引为1,2,3的元素
>>> list
[1, 5, 6]
>>> del list[:] #清空列表
>>> list
[]
>>> del list #删除实体变量
>>> list
<class 'list'>
# 7.元组(Tuple)和序列
- 元组是由若干逗号分隔的值组成
- 元组定义时的括号
()可有可无,但是建议有
>>> t = 123,234,'Mofar','ming'
>>> t
(123, 234, 'Mofar', 'ming')
>>> t[1]
234
>>> t = (123,234,'Mofar','ming')
>>> t
(123, 234, 'Mofar', 'ming')
>>> t[1]
234
>>> t2 = ((1,2,3),('a','b','c','d'))
>>> t2
((1, 2, 3), ('a', 'b', 'c', 'd'))
>>> t2[1]
('a', 'b', 'c', 'd')
>>> t2[0][2]
3
# 8.集合(Set)
- 集合是一个无序不重复的集
- 功能用于消除重复元素和关系测试
- 用花括号`{}创建集合
- 创建空集合,必须用
set()而不是{},{}是创建空字典set()方法参数不接收数字- 推导式集合
>>> set1 = {1,2,3,4,1,2,3,6,7,5}
>>> set1
{1, 2, 3, 4, 5, 6, 7}
>>> set3=set('1123')
>>> set3
{'1', '3', '2'}
>>> set3=set(1123)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not iterable
>>> a = { x for x in range(20) if x%3==0}
>>> a
{0, 3, 6, 9, 12, 15, 18}
# 9.字典(Dict)
- 就是json格式
- 键值对集合,key-value,key是唯一的
{}创建空字典- 构造函数
dict直接从键值对元组列表中构建字典- 推导式
>>> d = {'first_name':'liu','middle_name':'ming','last_name':'yun','alias_name':'Mofar lau'}
>>> d
{'first_name': 'liu', 'middle_name': 'ming', 'last_name': 'yun', 'alias_name': 'Mofar lau'}
>>> d2 = {}
>>> d2
{}
>>> d3 = dict([('key1',1),('key2',2)])
>>> d3
{'key1': 1, 'key2': 2}
>>> d4 = { x : x*y for x in range(5) for y in range(5)}
>>> d4
{0: 0, 1: 4, 2: 8, 3: 12, 4: 16}
>>> d5 = dict(key1=123,key2=234,key3=345)
>>> d5
{'key1': 123, 'key2': 234, 'key3': 345}
# 10.遍历技巧
- 遍历字典时,可以 用字典的
items()方法直接读取key-value键值对- 遍历序列时,可以用
enumerate()函数得到索引位置和对应值- 要同时遍历多个序列时,可以用
zip()函数,需要注意的是遍历完最短的序列即结束。- 反向遍历序列,可以用
reversed()函数(自身reverse()方法会直接修改原列表)- 按顺序遍历序列,可以 使用
sorted()函数返回已排序的序列,并不修改原序列(自身sort()方法会直接修改原列表)
>>> d = {'key1': 123, 'key2': 234, 'key3': 345}
>>> for k,v in d.items():
... print(k,v)
...
key1 123
key2 234
key3 345
>>> list = ['liu','ming','yun']
>>> for i,v in enumerate(list):
... print(i,v)
...
0 liu
1 ming
2 yun
>>> list = ['liu','ming','yun']
>>> list2 = ['soul','Mofar','lau']
>>> for l,l2 in zip(list,list2):
... print(l,l2)
...
liu soul
ming Mofar
yun lau
>>> list = ['liu','ming','yun']
>>> list1 = ['soul','Mofar']
>>> for l,l1 in zip(list,list1):
... print(l,l1)
...
liu soul
ming Mofar
>>> list = ['liu','ming','yun']
>>> for v in reversed(list):
... print(v)
...
yun
ming
liu
>>> list= ['soul','lau','mofar']
>>> for v in sorted(list):
... print(v)
...
lau
mofar
soul
# Python3模块
# 1. 模块概念
- 模块是一个包含所有自定义函数和变量的文件,后缀名为
.py- 模块可以被其它模块导入,被导入的名称将被放入当前操作模块的符号表中
- 模块除了方法定义 ,还可以包括初始化代码,只在第一次被导入时执行,相当于构建函数。
- 每个模块有各自独立的符号表,在模块内部为所有函数当作全局符号表来使用
- 可以通过
model_name.item_name表示法来访问模块内的函数- 可以直接把模块内函数或变量的名称导入到当前操作模块
- 可以一次性把模块中的所有(函数,变量)名称都 导入到当前模块的字符表(不包括单一下划线开头的名字)
# 2. import语句
import module1[,module2][,...moduleN]
一个模块无论执行多少次
import,都只会被导入一次。
# 3. from ... import语句
from nodname import name1[,name2[,...nameN]]
此声明不会把整个模块导入到当前的命名空间中,它只会将模块里的name1,name2,...nameN函数引入进来
# 4. from ... import * 语句
from modname import *
此方法会导入modname模块的所有函数和变量(不包括下划线开头的)
# 5. __name__属性
- python文件的属性,通常用来编写一段程序自身运行和被引入时的执行代码
- 每个模块都有一个
__name__属性,当其值为__main__时,表明是模块自身在运行,否则是被引入
#!/usr/bin/python3
# filename: test_name.py
if __name__ == '__main__':
print('It is running by itself')
else:
print('It is running by others import')
PS E:\code\mofar\pytest> py test_name.py
It is running by itself
PS E:\code\mofar\pytest> py
>>> import test_name
It is running by others import
# 6. dir函数
内置的函数
dir()可以找到模块内定义的所有名称。以一个字符串列表的形式返回
>>> import test_name, sys
It is running by others import
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'sys', 'test_name']
>>> dir(test_name)
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']
>>> dir(sys)
['__breakpointhook__', '__displayhook__', '__doc__', '__excepthook__', '__interactivehook__', '__loader__', '__name__', '__package__', '__spec__', '__stderr__', '__stdin__', '__stdout__', '__unraisablehook__', '_base_executable', '_
clear_type_cache', '_current_exceptions', '_current_frames', '_debugmallocstats', '_enablelegacywindowsfsencoding', '_framework', '_getframe', '_getquickenedcount', '_git', '_home', '_stdlib_dir', '_vpath', '_xoptions', 'addaudithoo
k', 'api_version', 'argv', 'audit', 'base_exec_prefix', 'base_prefix', 'breakpointhook', 'builtin_module_names', 'byteorder', 'call_tracing', 'copyright', 'displayhook', 'dllhandle', 'dont_write_bytecode', 'exc_info', 'excepthook',
'exception', 'exec_prefix', 'executable', 'exit', 'flags', 'float_info', 'float_repr_style', 'get_asyncgen_hooks', 'get_coroutine_origin_tracking_depth', 'get_int_max_str_digits', 'getallocatedblocks', 'getdefaultencoding', 'getfile
systemencodeerrors', 'getfilesystemencoding', 'getprofile', 'getrecursionlimit', 'getrefcount', 'getsizeof', 'getswitchinterval', 'gettrace', 'getwindowsversion', 'hash_info', 'hexversion', 'implementation', 'int_info', 'intern', 'i
s_finalizing', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'orig_argv', 'path', 'path_hooks', 'path_importer_cache', 'platform', 'platlibdir', 'prefix', 'ps1', 'ps2', 'pycache_prefix', 'set_asyncgen_hooks', 'set_coroutine_origi
n_tracking_depth', 'set_int_max_str_digits', 'setprofile', 'setrecursionlimit', 'setswitchinterval', 'settrace', 'stderr', 'stdin', 'stdlib_module_names', 'stdout', 'thread_info', 'unraisablehook', 'version', 'version_info', 'warnop
tions', 'winver']
dir()函数如果没有指定参数则会列出当前定义的所有名称
# 7. 标准模块
- os模块:提供了与操作系统交互的函数,例如创建、移动、删除文件和目录,以及访问环境变量等
- sys模块:提供了与解释器和系统相关的功能,例如解释器的版本和路径,以及stdin、stdout和stderr相关的信息
- time模块:提供了处理时间的函数,例如获取当前时间、格式化日期和时间,计时等
- datetime模块:提供更高级的日期和时间处理函数,例如处理时区、计算时间差、计算日期差等
- random模块:提供了生成随机数的函数,例如生成随机整数、浮点数、序列等
- math模块:提供了数学函数,例如三角函数,对数函数,指数函数,常数等
- re模块:提供了正则表达式处理函数,可以用于文本搜索、替换、分割等
- json模块:提供了JSON编码和解码函数,可以将python对象转换成json格式,和从json格式中解析出python对象
- urllib模块:提供了访问网页和处理URL的功能,包括下载文件、发送HTTP请求、处理cookies等
# 8. 包
- 包是一种管理Python模块命名空间的形式,和
java类似- 目录只有包含一个叫
__init__.py的文件才会被认作是一个包- 每次可以只导入一个包里面的特定模块,或一个函数(类或变量)
import item.subitem1.subitem2形式导入,subitem2只可以是包名或模块名,不可以是模块里的类、函数或变量名from package import item形式导入,可以任意导入模块,子包,函数,类或变量等
#导入方式1,全路径导入模块(此方式一般用来导入标准库模块)
import top.mofar.oss.util.file_util
import os
#这样导入模块,必须要用全路径名来访问
top.mofar.oss.util.file_util.suffix(filename)
os.getcwd()
#导入方式2,一般用来导入自定义模块
from top.mofar.oss.util import file_util
#这样导入模块,类似java的import,使用格式:
file_util.suffix(filename)
#导入方式3,导入一个函数或变量
from top.mofar.oss.util.file_util import suffix
#这样导入函数或变量,类似java的静态导入方法或变量
suffix(filename)
# 9.从一个包中导入*
from top.mofar.oss.util import *
- 此语句会导入util目录下
__init__.py文件里的__all__变量指定的所有模块名字。
__all__ = ['file_util','date_util','error_util']
# Python3输入和输出
# 1. 输出格式化
命令行输出方式:
- 表达式语句
- print()函数
- write()方法/sys.stdout
- str():函数返回一个用户易读的表达形式
- repr():产生一个解释器易读的表达形式
#命令行模式
>>> s = 'Hello, Crazy Mofar'
>>> str(s)
'Hello, Crazy Mofar'
>>> repr(s)
"'Hello, Crazy Mofar'"
>>> str(1/3)
'0.3333333333333333'
>>> repr(1/3)
'0.3333333333333333'
>>> x = 10 * 3.14
>>> y = 6.25 * 210
>>> s = 'x的值为:' + repr(x) + ', y的值为:' + repr(y)
>>> print(s)
x的值为:31.400000000000002, y的值为:1312.5
>>> s = 'x的值为:' + str(x) + ', y的值为:' + str(y)
>>> print(s)
x的值为:31.400000000000002, y的值为:1312.5
#repr()函数可以转义字符串中的特殊字符,即原样输出
>>> welcome = "Hello, \nWelcome!"
>>> print(repr(welcome))
'Hello, \nWelcome!'
>>> print(str(welcome))
Hello,
Welcome!
#repr()的参数可以 是Python任意对象
>>> repr((x, y,('Soul','Mofar')))
"(31.400000000000002, 1312.5, ('Soul', 'Mofar'))"
>>> str((x, y,('Soul','Mofar')))
"(31.400000000000002, 1312.5, ('Soul', 'Mofar'))"
PS E:\code\mofar\pytest> py
Python 3.11.2 (tags/v3.11.2:878ead1, Feb 7 2023, 16:38:35) [MSC v.1934 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
# rjust(num)方法靠右对齐,并补左边空格,类似的方法还有:ljust(num):左对齐,center(num)中间对齐,zfill(num)左边补0
>>> for x in range(1,11):
... print(repr(x).rjust(2), repr(x*x).rjust(3),repr(x*x*x).rjust(4))
...
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
>>> for x in range(1,11):
... print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))
...
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
#str.format()类似log4j的格式化,括号和里面的字符将会被format的参数替换,括号中的数字表示format中的参数位置,冒号后面是格式,可以省略
# 参数也可以使用关键字参数指定,或位置参数和关键字参数混合使用
>>> print('{0}, {name},{1}'.format('Hi','welcome',name='Mofar'))
Hi, Mofar,welcome
!a:即ascii(),!s即str(),!r即repr(),可以用于格式化值之前对其先进行转化。
>>> print('Hi,{!r},come here!'.format('Mofar\n'))
Hi,'Mofar\n',come here!
>>> print('圆周率约等于:{0:.3f}'.format(3.1415926))
圆周率约等于:3.142
>>> rectangle = {'x': 12, 'y': 100, 'z': 13}
>>> for name, size in rectangle.items():
... print('{0:5} ==> {1:5d}'.format(name,size))
...
x ==> 12
y ==> 100
z ==> 13
>>> print('x:{0[x]:d};y:{0[y]:d},z:{0[z]:d}'.format(rectangle))
x:12;y:100,z:13
>>> print('x:{x:d};y:{y:d},z:{z:d}'.format(**rectangle))
x:12;y:100,z:13
# 2. 旧式字符串格式化
和
C语言的printf格式化类似,采用%后接格式进行格式化,参数值用%来接建议使用str.format()
>>> print('圆周率的值约等于:%3.2f。' % 3.1415926)
圆周率的值约等于:3.14。
# 3. 键盘输入
- python提供了
input()内置函数从标准输入处读入一行文本,默认的标准输入是键盘。
#!/usr/bin/python
s = input('Please input:')
print('你输入的内容是:', s)
#Output result
#Please input:liu mingyun
#你输入的内容是: liu mingyun
#Process finished with exit code 0
>>> input('Please input:')
Please input:Mofar, welcome
'Mofar, welcome'
# 4. 读写文件
- 提供了一个
open()内置函数来打开一个file对象- 格式:
open(filename, mode)
- filename: 文件路径和文件名的字符串值
- mode:可选参数,文件的打开模式:只读
r,写入w,追加a,二进制b等,默认是只读r
# 文件打开模式的完全列表
| 模式 | 说明 |
|---|---|
| r | 只读方式打开文件,文件的指针指向文件的开头。这是默认模式 |
| rb | 以二进制格式且只读的方式打开一个文件,文件指针指向文件的开头 |
| r+ | 打开一个文件用于读写,文件指针指向文件的开头 |
| rb+ | 以二进制格式且读写的文件打开一个文件,文件指针指向文件的开头 |
| w | 打开一个文件用于写入,文件存在则打开文件并从头开始编辑,即覆盖原来的内容;文件不存在则新建 |
| wb | 以二进制格式打开文用于写入,文件存在则打开文件并从头开始编辑,即覆盖原有的内容;文件不存在则新建 |
| w+ | 以二进制格式打开文件用于读写。文件存在则打开文件并从头开始编辑,即覆盖原有内容;文件不存在则新建 |
| wb+ | 以二进制格式打开文件用于读写。文件存在则打开文件并从头开始编辑,即覆盖原有内容;文件不存在则新建 |
| a | 打开文件用于追加。文件存在则文件指针指向文件的结尾;新内容接在已有内容之后。文件不存在则新建文件进行写入 |
| ab | 以二进制格式打开文件用于追加。文件存在则指针指向文件结尾;新内容接在已有内容之后。文件不存在则新建文件进行写入 |
| a+ | 打开文件用于读写。文件存在则指针指向文件结尾,文件打开时是追加模式文件不存在则新建用于读写 |
| ab+ | 以二进制格式打开文件用于追加。文件存在则指针指向文件结尾;不存在则新建用于读写 |
# 总结
| 模式 | r | r+ | w | w+ | a | a+ |
|---|---|---|---|---|---|---|
| 读 | * | * | * | * | ||
| 写 | * | * | * | * | * | |
| 创建 | * | * | * | * | ||
| 覆盖 | * | * | ||||
| 指针在开始 | * | * | * | * | ||
| 指针在结尾 | * | * |
#!/usr/bin/python3
# Open a file
def write1():
f = open('E:/code/mofar/pytest/test_file.txt', 'w')
f.write('2Python is the best computer‘s language!! Goodness\n')
f.write('Python is the best computer‘s language!! Goodness\n')
f.close()
return
def write2():
f = open('E:/code/mofar/pytest/test_file.txt', 'a')
f.write('我是新加的内容,接在后面的\n')
f.write('\n')
f.write('\n')
f.write('我是新加的内容,接在后面的12')
f.close()
return
def read1():
f = open('E:/code/mofar/pytest/test_file.txt', 'r')
s = f.read()
print(s)
f.close()
def read2():
f = open('E:/code/mofar/pytest/test_file.txt', 'r')
print(f.readline())
print(f.readline())
print('readlines方法读剩下的内容:')
print(f.readlines())
f.close()
return
if __name__ == '__main__':
write1()
write2()
# read1()
read2()
else:
print('hehe')
#2Python is the best computer‘s language!! Goodness
#
#Python is the best computer‘s language!! Goodness
#
#readlines方法读剩下的内容:
#['我是新加的内容,接在后面的\n', '\n', '\n', '我是新加的内容,接在后面的12']
#
# 5. 文件对象的方法
f.read(size):读取size长度的文件内容,-1或默认则返回所有内容f.readline(size):从一行内读取size长度的内容,返回空字符串表示读取到最后一行f.readlines():读取所有行的内容,返回数组形式f.write(string):将string的内容写入到文件中,并返回写入的字符数,写入的不是字符串,要先用str()进行格式转换f.tell():返回文件指针当前的位置,它是从文件开头算起的字符数f.seek(offset, whence):按字符数移动指针位置,whence的取值为0, 1, 2
seek(offset, 0):指针从文件开头移动offset个字符,适用于没有b打开的文件,默认方法seek(offset, 1):指针从当前位置移动offset个字符,不适用于没有b打开的文件seek(offset, 2):指针从文件结尾往前移动offset个字符,不适用于没有b打开的文件- seek一般是操作b模式打开的文件,对于没b打开的文件,移动位置只有从文件开头移动
f.close():关闭文件释放资源
# 6. pickle模块
pickle模块实现基本的数据序列化和反序列化(一个file文件可以保存多个数据对象)
pckl.dump(obj, file, [,protocol]):把数据对象保存到文件中pickle.load(file):从file中读取字符串,并把它重构成原来的数据对象
#!/usr/bin/python3
import pickle
import pprint
data1 = {'first_name': 'liu', 'middle_name': 'ming', 'last_name': 'yun', 'description': ('一个人的描述', '一生的故事'),
'resume': {'weight': 65, 'high': 171}}
data2 = ('liu', 'ming', 'yun', 'mofar', 'soul', '刘名云', 19)
def dmp():
output = open('data_file.pkl', 'wb')
pickle.dump(data1, output)
pickle.dump(data2, output)
output.close()
return
def ld():
pckl_file = open('data_file.pkl', 'rb')
d1 = pickle.load(pckl_file)
pprint.pprint(d1)
d2 = pickle.load(pckl_file)
pprint.pprint(d2)
pckl_file.close()
return
if __name__ == '__main__':
dmp()
ld()
result:
{'description': ('一个人的描述', '一生的故事'),
'first_name': 'liu',
'last_name': 'yun',
'middle_name': 'ming',
'resume': {'high': 171, 'weight': 65}}
('liu', 'ming', 'yun', 'mofar', 'soul', '刘名云', 19)
# Python3 文件操作
# 1. open()方法
简单语法格式
open(file,mode='r')
完整语法格式
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
file:必填,文件路径(绝对或相对路径)mode:可选,文件打开模式,默认模式是rtbuffering:设置缓冲encoding:一般使用utf-8errors:报错级别newline:区分换行符closefd:传入的file参数类型
mode参数说明:
涉及到的字符有
r,w,x,a,b,t,+
| 模式组合 | 解释 |
|---|---|
| t | 文本模式打开(默认) |
| b | 二进制模式打开 |
| x | 写模式,新建一个文件,如果该文件存在则报错 |
| r | 只读模式,指针放在文件开头,一般处理非文本文件或图片等 |
| w | 写模式,文件存在则打开,如果文件存在则打开从头开始编辑,旧内容删除,文件不存在则新建 |
| + | 打开一个文件进行更新(读写模式) |
| a | 文件写追加,文件存在则指针指向结尾,不存在则创建 |
| rb | 二进制格式读一个文件,指针在开头。 |
| r+ | 读写模式,指针在开头 |
| wb | 二进制写模式,指针在开头,覆盖原有内容,文件不存在则新建 |
| w+ | 读写模式,指针在开头,覆盖原有内容,文件不存在则新建 |
| wb+ | 二进制读写模式,指针在开头,覆盖原有内容,文件不存在则新建 |
| ab | 二进制追加写模式,不存在则新建 |
| a+ | 读写追加模式,不存在则新建 |
| ab+ | 二进制读写追加模式,不存在则新建 |
- 读r写w的指针都在开头,读需要文件存在,写时文件不存在则新建
- 追加a的指针在结尾,写时文件不存在则新建
# 2. file对象
file对象用open函数创建
| method | description |
|---|---|
| file.close() | close file |
| file.flush() | 刷新文件内部缓冲,直接把缓冲区数据写入文件 |
| file.fileno() | 返回一个整型的文件描述符(file descriptor FD整型) |
| file.isatty() | 文件连接到终端设备返回True,否则返回False |
| file.read([size]) | 从文件读取指定的字节数,空或负数则读取全部 |
| file.readline([size]) | 读取整行,包括换行'\n'字符 |
| file.readlines[sizeint] | 读取所有行并返回列表 |
| file.seek(offset[,whence]) | 移动指针到指定位置 |
| file.tell() | 返回指针当前位置 |
| file.truncate([size]) | 从文件的首行首字符开始截断size个字符,无size表示从当前位置截断,截断之后后面的内容清空 |
| file.write(str) | 将字符串写入文件,返回的是写入的字符长度 |
| file.writelines(sequence) | 向文件写入一个序列字符串列表,若需换行则在内容里加入换行符 |
# Python3 OS 文件/目录方法
# 方法列表
| 方法 | 说明 |
|---|---|
| os.access(path, mode) | 检验权限模式 |
| os.chdir(path) | 改变当前工作目录 |
| os.chflags(path, flags) | 设置路径的标记为数字标记 |
| os.chmod(path, mode) | 更改权限 |
| os.chown(path, uid, gid) | 更改文件所有者 |
| os.chroot(path) | 改变当前进程的根目录 |
| os.close(fd) | 关闭文件描述符fd |
| os.closerange(fd_start, fd_end) | 关闭所有文件描述符,从fd_start(包含)到fd_end(不包括),错误会忽略 |
| os.dup(fd) | 复制文件描述符fd |
| os.dup2(fd1, fd2) | 将一个文件描述符fd1复制到另一个fd2 |
| os.fchdir(fd) | 通过文件描述符改变当前工作目录 |
| os.fchmod(fd, mode) | 改变目录一个文件的访问权限,该文件由参数fd指定,参数mode是Unix下的文件访问权限 |
| os.fchown(fd, uid, gid) | 修改一个文件的所有权,这个函数修改一个文件的用户ID和用户组ID,该文件由文件描述符fd指定 |
| os.fdatasync(fd) | 强制将文件写入磁盘,该文件由文件描述符fd指定,但是不强制更新文件的状态信息 |
| os.fdopen(fd[, mode[, bufsize]]) | 通过文件描述符fd创建一个文件对象,并返回这个文件对象 |
| os.fpathconf(fd, name) | 返回一个打开的文件系统配置信息,name为检索的系统配置信息的值,它也许是一个定义系统值的字符串,这些名字在很多标准中指定 |
| os.fstat(fd) | 返回文件描述符fd的状态,像stat() |
| os.fstatvfs(fd) | 返回包含文件文件描述符fd的文件的文件系统的信息 |
| os.fsync(fd) | 强制将文件描述符为fd的文件写入硬盘 |
| os.ftruncate(fd, length) | 裁剪文件描述符fd对应的文件,所以它最大不能超过文件大小 |
| os.getcwd() | 返回当前工作目录 |
| os.getcwdb() | 返回一个当前工作目录的Unicode对象 |
| os.isatty(fd) | 如果文件描述符fd是打开的, 并与tty(-like)设备相连,则返回True,否则False |
| os.lchflags(path, flags) | 设置路径的标记为数字标记,类似chflags(),但是没有软链接 |
| os.lchmod(path, mode) | 修改连接文件权限 |
| os.lchown(path, uid, gid) | 更新文件所有者,类似chown,但是不追踪链接 |
| os.link(src, dst) | 创建硬链接,名为参数dst,指定参数src |
| os.listdir(path) | 返回path指定的文件夹包含的文件或文件夹的名字的列表 |
| os.lseek(fd, pos, how) | 设置文件描述符fd当前位置为pos,how方式修改:0从文件开始计算pos,1从当前位置计算pos,2则从文件结尾开始计算pos |
| os.lstat(path) | 像stat(),但是没有软链接 |
| os.major(device) | 从原始设备号中提取设备major号码(使用stat的st_dev或st_rdev field) |
| os.makedev(major, minor) | 用major和minor设备号组成一个原始设备号 |
| os.makedirs(path[, mode]) | 递归文件夹创建函数 |
| os.minor(device) | 从原始设备号中提取设备minor号码 |
| os.mkdir(path[, mode]) | 以数字mode创建一个名为path的文件夹,默认的mode值为0777 |
| os.mkfifo(path[, mode]) | 创建命名管道,mode为数字,默念为0666 |
| os.mknod(filename[, mode=0600, device]) | 创建名为filename的文件系统节点 |
| os.open(file, flags[, mode]) | 打开一个文件,并且设置需要的打开主页选项,mode参数是可选的· |
| os.openpty() | 打开一个新的伪终端对,返回pty和tty的文件描述符 |
| os.pathconf(path, name) | 返回相关文件的系统配置信息 |
| os.pipe() | 创建一个管道,返回一对文件描述符(r,w)分别为读和写 |
| os.popen(command[, mode[, bufsize]]) | 从一个命令打开一个管道 |
| os.read(fd, n) | 从文件描述符fd中读取最好n个字节,返回包含读取字节的字符串,文件描述符fd对应文件结束则返回空字符串 |
| os.readlink(path) | 返回软连接所指向的文件 |
| os.remove(path) | 删除路径为path的文件。如果path是一个文件夹则抛OSError |
| os.removedirs(path) | 递归删除目录 |
| os.rename(src, dst) | 重命名文件或目录 |
| os.renames(old, new) | 递归地对目录进行更名,也可以对文件进行更名 |
| os.rmdir(path) | 删除空目录,非空则抛OSError异常 |
| os.stat(path) | 返回指定路径信息 |
| os.stat_float_times([True|False]) | 是否以float形式返回时间戳 |
| os.statvfs(path) | 获取指定路径的文件系统统计信息 |
| os.symlink(src, dst) | 创建软链接,相当于ln -s src dst |
| os.tcgetpgrp(fd) | 返回与终端fd关联的进程组 |
| os.tcsetpgrp(fd, pg) | 设置与终端fd关联的进程组为pg |
| os.ttyname(fd) | 返回与文件描述符fd关联的终端设备名,如果fd没有与终端设备关联,则抛异常 |
| os.unlink(path) | 删除文件,path是目录则抛异常 |
| os.utime(path, times) | 返回指定文件的访问和修改的时间 |
| os.walk(top[, topdown=True[,onerror=None[, followlinks=False]]]) | 输出在文件夹中的文件名通过在树中游走,向上或向下 |
| os.write(fd, str) | 写入字符串到文件描述符fd中,返回实际写入的字符串长度 |
| os.path模块 | 获取文件的属性信息 |
| os.pardir() | 当前目录的父目录,以字符串形式显示目录名 |
| os.replace(src,dst) | 重命名文件或目录 |
# os.access(path, mode)
# 概述
使用当前的`uid/gid检测路径的权限,存在可读可写可执行
# 语法
os.access(path, mode)
# 参数
- path:待检测的路径
- mode的取值
os.F_OK:是否存在os.R_OK:是否可读os.W_OK:是否可写os.X_OK:是否可执行
# 返回值
返回True或False
# 实例
#!/usr/bin/python3
# filename:os_access_pratice.py
# os练习
import os
def practice_access(path):
file_exist = os.access(path, os.F_OK)
print('F_OK - 返回值是 {}'.format(file_exist))
file_readable = os.access(path, os.R_OK)
print('R_OK - 返回值是 {}'.format(file_readable))
file_writable = os.access(path, os.W_OK)
print('W_OK - 返回值是 {}'.format(file_writable))
file_executable = os.access(path, os.X_OK)
print('X_OK - 返回值是 {}'.format(file_executable))
return
if __name__ == '__main__':
practice_access('not/exist/path/or/file')
practice_access('os_access_pratice.py')
practice_access('/os_access_pratice.py')
else:
pass
F_OK - 返回值是 False
R_OK - 返回值是 False
W_OK - 返回值是 False
X_OK - 返回值是 False
F_OK - 返回值是 True
R_OK - 返回值是 True
W_OK - 返回值是 True
X_OK - 返回值是 True
F_OK - 返回值是 True
R_OK - 返回值是 True
W_OK - 返回值是 True
X_OK - 返回值是 True
# os.chdir(path)
# 概述
改变当前工作目录到指定的路径,和bash的cd path一样
# 语法
os.chdir(path)
# 参数
- path:要跳转到的新路径
# 返回值
None
# 实例
#!/usr/bin/python3
# filename:os_chdir_pratice.py
import os
def practice_chdir():
print('当前工作目录是{}'.format(os.getcwd()))
new_dir = "E:/code/mofar/pytest/test1"
os.chdir(new_dir)
print('当前工作目录是{}'.format(os.getcwd()))
return
if __name__ == '__main__':
practice_chdir()
else:
pass
当前工作目录是E:\code\mofar\pytest
当前工作目录是E:\code\mofar\pytest\test1
# os.chmod(path, mode)
# 概述
修改文件或目录的权限,类似于chmod 755 dir
# 语法
os.chmod(path,mode)
# 参数
- path:待操作的目录或路径
- mode: 和linux的chmod一样,不过值是8进制(0o开头),在stat模块里定义了相应的数字,可以按位或操作生成全部的权限值。
- stat.S_IXUSR:0o100
- stat.S_IRUSR:0o200
- stat.S_IWUSR:0o400
- stat.S_IRWXU:0o700
# 返回值
None
# 实例
#!/usr/bin/python3
# filename:os_chmod_pratice.py
# os练习
import os
import stat
def practice_chmod(path):
os.chmod(path,stat.S_IRWXU)
print('执行成功')
return
if __name__ == '__main__':
practice_chmod('os_chmod_pratice.py')
else:
pass
# os.chown(path, uid, gid)
# 概述
更改文件或目录的所有者,如果不修改可以把值设置为-1。
# 语法
os.chown(path, uid, gid)
# 参数
- path:文件或目录
- uid:所属用户ID
- gid:所属用户组ID
# 返回值
None
# 实例
#!/usr/bin/python3
# filename:os_chown_pratice.py
# os练习
import os
import stat
def practice_chown(path):
os.chown(path,1,-1)
print('执行成功')
return
if __name__ == '__main__':
practice_chown('os_chown_file.txt')
else:
pass
# os.chroot(path)
# 概述
更改当前进程的根目录为指定目录
# 语法
os.chroot(path)
# 参数
- path:要设置为根目录的目录
# 返回值
None
# 实例
#!/usr/bin/python3
import os, sys
os.chroot(''/tmp')
print('执行成功')
# os.close(fd)
# 概述
用于关闭指定的文件描述符fd
# 语法
os.close(fd)
# 参数
fd文件描述符
# 返回值
None
# 示例
#!/usr/bin/python3
# filename:os_close_pratice.py
# os练习
import os
def practice_close(path):
f = os.open(path, os.O_RDWR | os.O_CREAT)
os.write(f, b'this is my first computer program')
os.close(f)
print('执行成功')
return
if __name__ == '__main__':
practice_close('os_close.txt')
else:
pass
# os.closerange(fd_start, fd_end)
# 概述
关闭从fd_start(包括)到fd_end(不包括)的文件描述符,错误会忽略掉
# 语法
os.closerange(fd_start, fd_end)
# 参数
- fd_start:最小文件描述符
- fd_end:最大文件描述符,不包括此值
# 返回值
None
# 示例
#!/usr/bin/python3
import os
fd = os.open('file.txt', os.O_RDWR|os.O_CREAT)
os.write(fd, b'This is test')
os.closerange(fd, fd)
print('执行成功')
# os.dup(fd)复制文件描述符
# 概述
用于复制文件描述符
# 语法
os.dup(fd)
# 参数
- fd:文件描述符
# 返回值
返回复制的文件描述符
# 示例
#!/usr/bin/bash
import os
def os_dup():
fd = os.open('os_dup_file.txt', os.O_RDWR | os.O_CREAT)
d_fd = os.dup(fd)
os.write(d_fd, 'This is os.dup test'.encode())
os.closerange(fd, d_fd)
print('close all file success!')
return
if __name__ == '__main__':
os_dup()
# os.dup2(fd,fd2)
# 概述
将一个文件描述符src_fd复制到另一个文件描述符dst_fd2
# 语法
os.dup2(src_fd, dst_fd2)
# 参数
- src_fd:源文件描述符
- dst_fd2:复制的新文件描述符
# 返回值
None
# 示例
#!/usr/bin/python3
import os
def os_dup2():
file = open('os_dup2_file.txt', 'a')
# 把此文件的文件描述符,复制到1描述符,1描述方法符就是stdout
os.dup2(file.fileno(), 1)
file.close()
print('mofar')
print('Soul')
if __name__ == '__main__':
os_dup2()
# os.fchdir(fd)
# 概述
通过文件描述符改变当前工作目录
# 语法
os.fchdir(fd)
# 参数
- fd:文件描述符
# 返回值
None
# 示例
#!/bin/bash/python
import os
# run in Unix/linux platform
def os_fchdir():
# change to current test direction
os.chdir('/tmp')
print('current working direction is %s' % os.getcwd())
# open new direction
fd = os.open('/var', os.O_RDONLY)
# change to new direction
os.fchdir(fd)
print('current working direction is %s' % os.getcwd())
os.close(fd)
if __name__ == '__main__':
os_fchdir()
# os.fchmod(fd, mode)
# 概述
修改文件描述符指向的文件的访问权限
# 语法
os.fchmod(df, mode)
# 参数
- fd:文件描述符
- mode:文件的访问模式,由以下一个或多个组成,多个用'|'隔开
- stat.S_ISUID:设置UID位
- stat.S_ISGID:设置组ID位
- stat.S_ENFMT:系统文件锁定的执法行动
- stat.S_ISVTX:在执行之后保存文件和图片
- stat.S_IREAD:对于所有者读的权限
- stat.S_IWRITE:对于所有者写的权限
- stat.S_IEXEC:对于所有者执行的权限
- stat.S_IRWXU:对于所有者读写执行的权限
- stat.S_IRUSR:所有者读的权限
- stat.S_IWUSR:所有者写的权限
- stat.S_IXUSR:所有者执行的权限
- stat.S_IRWXG:所有者读写执行的权限
- stat.S_IRGRP:
- stat.S_IWGRP:
- stat.S_IXGRP:
- stat.S_IRWXO:
- stat.S_IROTH:
- stat.S_IWOTH:
- stat.S_IXOTH:
# 返回值
# 示例
未完待续………………
← python